A surprise
I came to write this post because I was surprised by its findings.
The seed for it came from a somewhat obscure source: the Tokyo.R slack channel.
This is actually a fairly vibrant R community. In any case, there was a post by an R user suprised to find parallel computation much slower than the sequential alternative - even though he had thousands, tens of thousands of ‘embarassingly parallel’ iterations to compute.
He demonstrated this with a simple benchmarking exercise, which showed a variety of parallel map functions from various packages (which shall remain nameless), each slower than the last, and (much) slower than the non-parallel versions.
The replies to this post could be anticipated, and mostly aimed to impart some of the received wisdom: namely that you need computations to be sufficiently complex to benefit from parallel processing, due to the extra overhead from sending and coordinating information to and from workers. For simple functions, it is just not worth the effort.
And this is indeed the ‘received wisdom’…
and I thought about it… and the benchmarking results continued to look really embarassing.
The implicit answer was just not particularly satisfying:
‘sometimes it works, you just have to judge when’.
And it didn’t really answer the original poster either - for he just attemped to expose the problem by using a simple example, not that his real usage was as simple.
The parallel methods just didn’t work. Or rather didn’t ‘just work’TM.
And this is what sparked off The Investigation.
The Investigation
It didn’t seem right that there should be such a high bar before parallel computations become beneficial in R.
My starting point would be mirai, somewhat naturally (as I’m the author). I also knew that mirai would be fast, as it was designed to be minimalist.
mirai? That’s みらい or Japanese for ‘future’. All you need to know for now is that it’s a package that can create its own special type of parallel clusters.
I had not done such a benchmarking exercise before as performance itself was not its raison d’être. More than anything else, it was built as a reliable scheduler for distributed computing. It is the engine that powers crew, the high performance computing element of targets, where it is used in industrial-scale reproducible pipelines.
And this is what I found:
Applying the statistical function rpois() over 10,000 iterations:
library(parallel)
library(mirai)
base <- parallel::makeCluster(4)
mirai <- mirai::make_cluster(4)
x <- 1:10000
res <- microbenchmark::microbenchmark(
parLapply(base, x, rpois, n = 1),
lapply(x, rpois, n = 1),
parLapply(mirai, x, rpois, n = 1)
)
ggplot2::autoplot(res) + ggplot2::theme_minimal()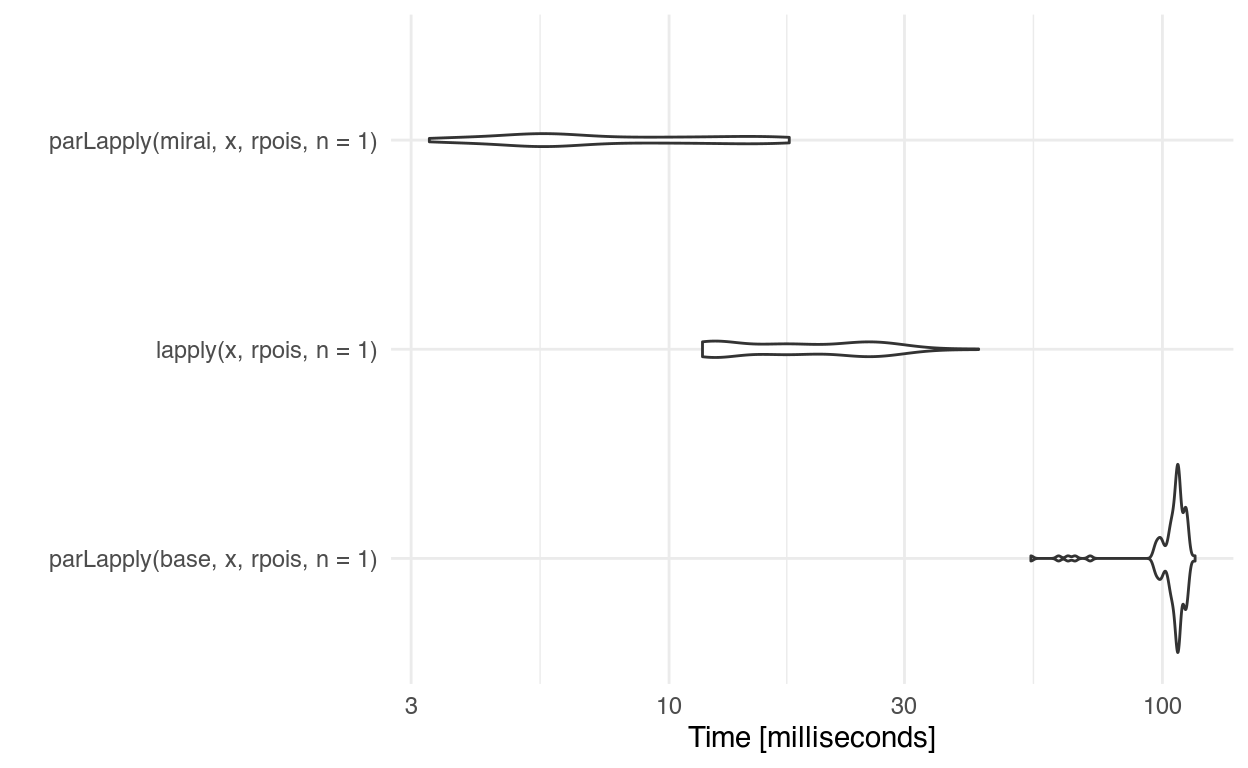
Using the ‘mirai’ cluster resulted in faster results than the simple non-parallel lapply(), which was then in turn much faster than the base default parallel cluster.
Faster!
I’m only showing the comparison with base R functions. They’re often the most performant after all. The other packages that had featured in the original benchmarking suffer from an even greater overhead than that of base R, so there’s little point showing them above.
Let’s confirm with an even simpler function…
Applying the base function sum() over 10,000 iterations:
res <- microbenchmark::microbenchmark(
parLapply(base, x, sum),
lapply(x, sum),
parLapply(mirai, x, sum)
)
ggplot2::autoplot(res) + ggplot2::theme_minimal()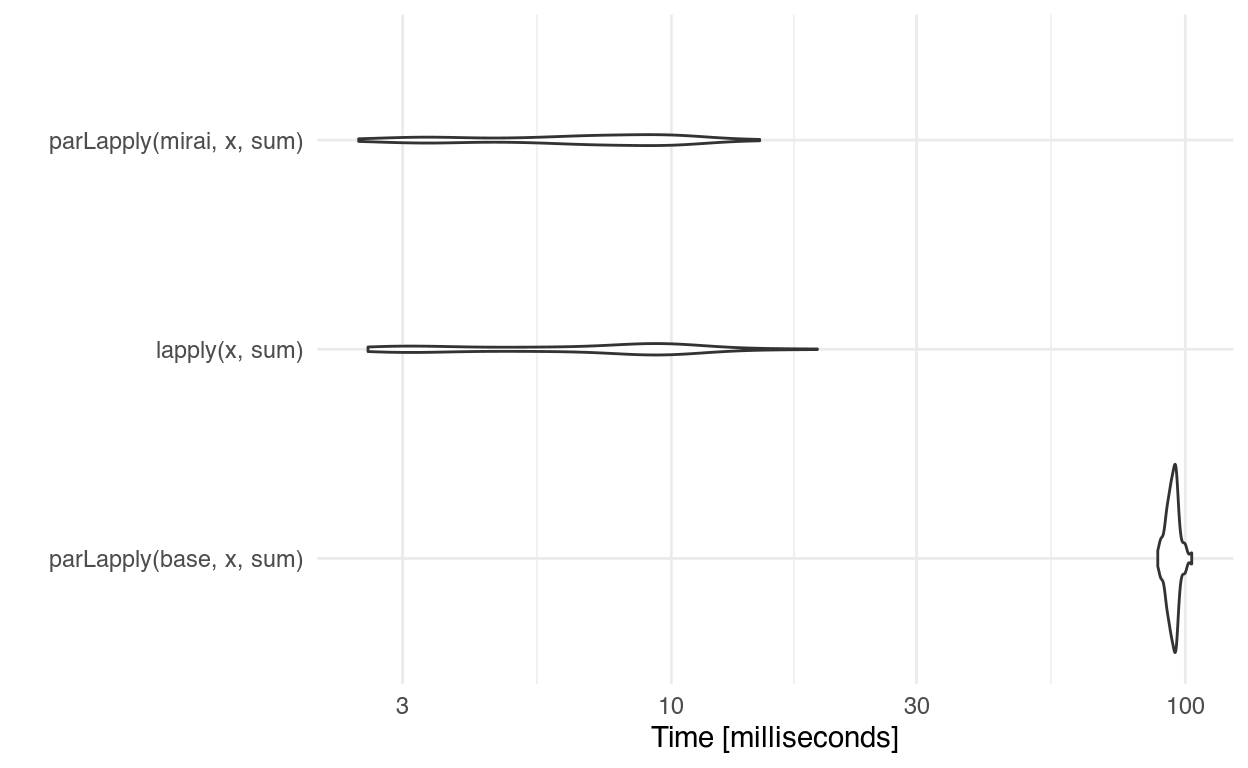
mirai holds its own! Not much faster than sequential, but not slower either.
But what if the data being transmitted back and forth is larger, would that make a difference? Well, let’s change up the original rpois() example, but instead of iterating over lamba, have it return increasingly large vectors instead.
Applying the statistical function rpois() to generate random vectors around length 10,000:
x <- 9900:10100
res <- microbenchmark::microbenchmark(
parLapplyLB(base, x, rpois, lambda = 1),
lapply(x, rpois, lambda = 1),
parLapplyLB(mirai, x, rpois, lambda = 1)
)
ggplot2::autoplot(res) + ggplot2::theme_minimal()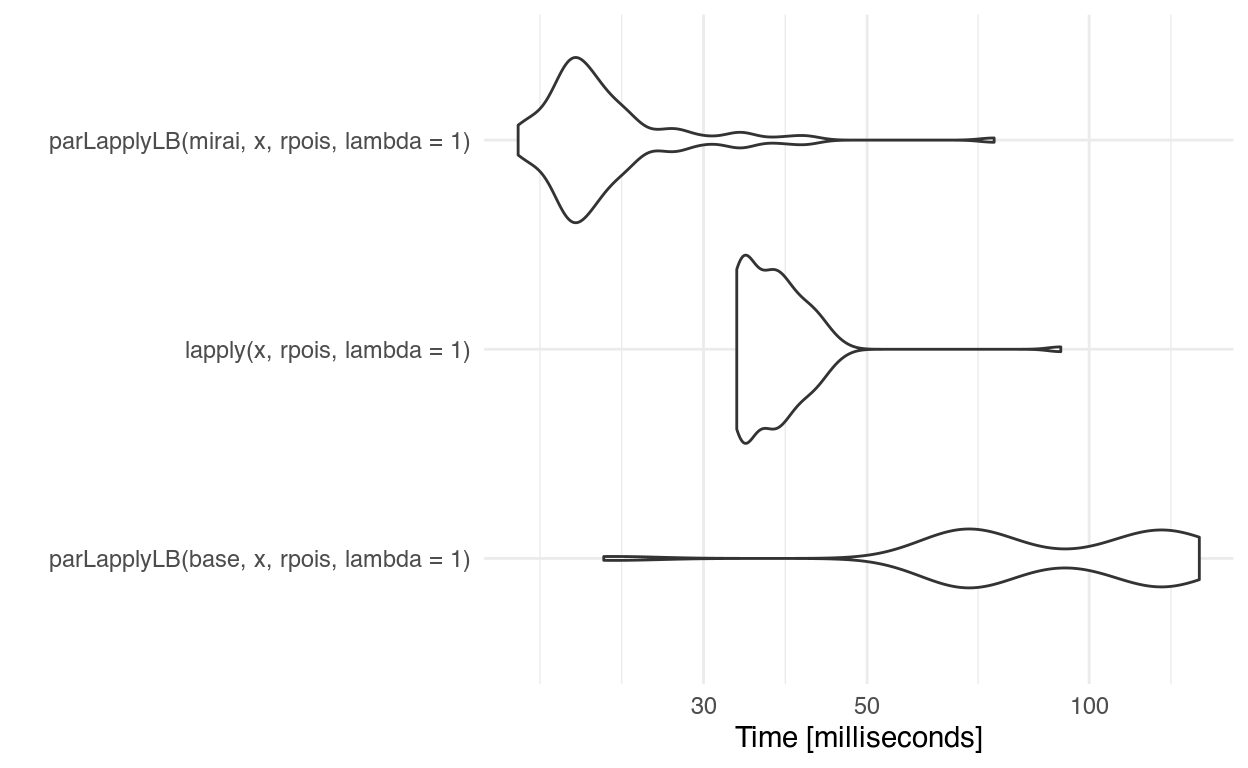
The advantage is maintained! 1
So ultimately, what does this all mean?
Well, quite significantly, that virtually any place you have ‘embarassingly parallel’ code where you would use lapply() or purrr::map(), you can now confidently replace with a parallel parLapply() using a ‘mirai’ cluster.
The answer is no longer ‘sometimes it works, you just have to judge when’, but:
‘yes, it works!’.
What is this Magic
mirai uses the latest NNG (Nanomsg Next Generation) technology, a lightweight messaging library and concurrency framework
2 - which means that the communications layer is so fast that this no longer creates a bottleneck.
The package leverages new connection types such as IPC (inter-process communications), that are not available to base R. As part of R Project Sprint 2023, R Core invited participants to provide alternative commnunications backends for the parallel package, and ‘mirai’ clusters were born as a result.
A ‘mirai’ cluster is simply another type of ‘parallel’ cluster, and are persistent background processes utilising cores on your own machine, or on other machines across the network (HPCs or even the cloud).
I’ll leave it here for this post. You’re welcome to give mirai a try, it’s available on CRAN and at https://github.com/shikokuchuo/mirai.